学院新闻
College News

近日,中国计算机学会(CCF)推荐的A类国际学术会议ACM Multimedia 2023论文接收结果公布,伟德国际1946源自英国金琴教授团队AIM3多媒体计算实验室有3篇长文被录用。国际多媒体学术会议(ACM International Conference on Multimedia,简称ACM MM)由国际计算机协会(ACM)发起,是多媒体处理、分析与计算领域具有影响力的国际会议。
3篇论文第一作者分别是来自AIM3多媒体计算实验室的2020级硕士生刘宇辰、2021级博士生杨丁一、2023级博士生许博深。
论文介绍
1. 论文题目:Emotionally Situated Text-to-Speech Synthesis in User-Agent Conversation
作者:刘宇辰, 张昊宇, 刘世超, 殷翔, 马泽君, 金琴
通讯作者:金琴
论文概述:
对话场景下的文本-语音合成(Conversational Text-to-speech Synthesis, Conversational TTS)任务的目的是在人机语音对话场景下,为语音助理(Agent)生成符合当前场景的音频,这要求合成语音的情感、风格等属性适合当前场景。
对于该任务,先前的工作已经做出了一定的探索,先前工作普遍利用对话历史中的上下文信息,为agent提供风格信息,但这些工作依然存在两方面的不足:第一,它们对多模态上文的利用有待提高,有些工作仅仅使用了对话中的文本信息,忽略了用户的语音,有些工作则忽略了用户与助理的角色不同,没有将其语音分别进行建模;第二,以前的工作忽略了用户和助理之间的情感依赖,包括:1)agent理解用户的情感状态,2)agent在生成的语音中表达适当的情感。
在这项工作中,我们提出了一个“情感适应”的文本到语音合成框架EmoSit-TTS,理解用户的语义和潜在的情感等状态,并为用户-代理对话中的代理生成具有适当的说话风格和情感表达的语音。
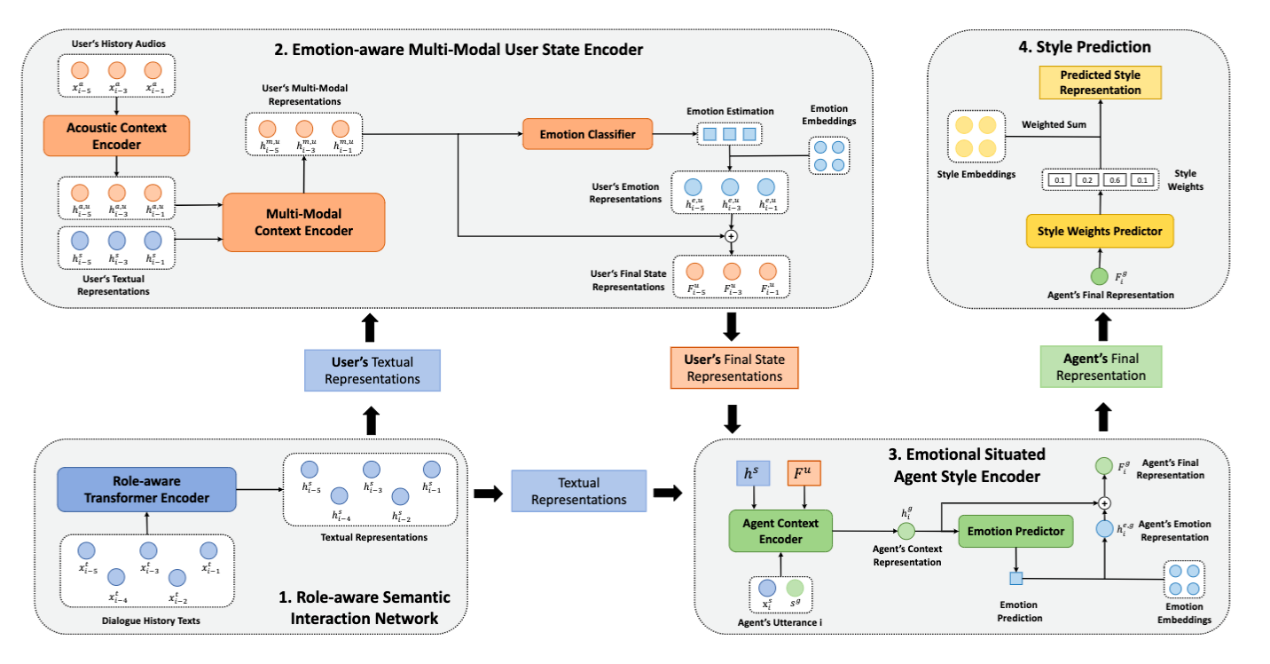
具体地,EmoSit-TTS框架包含两个部分,分别是建模用户-助理对话的历史信息并为助理提供情感与风格表征的结构,该结构如上图所示;第二部分是常用的声学模型FastSpeech2与声码器HiFi-GAN组成的语音合成系统,在此不再详细介绍。
如上图所示,在建模对话历史信息时,EmoSit-TTS首先分别建模用户和助理所说出的文本信息,随后针对性地建模用户的多模态信息交互,并预测用户的情感,以便更好地理解用户;随后,基于对对话历史和用户状态的理解,EmoSit-TTS通过注意力模块将其总结为当前句子中助理的状态,并预测助理应有的情感;最后,模型将助理的情感融入风格表征中,从而合成出风格与情感适合当前场景的语音。
在DailyTalk数据集上的实验表明,我们提出的框架在用户-代理对话场景下,合成的语音表达力具有优势,尤其是与情感相关的表达力。
2. 论文题目:Visual Captioning at Will: Describing Images and Videos Guided by a Few Stylized Sentences
作者: 杨丁一,陈泓宇,侯兴林,葛铁铮,姜宇宁,金琴
通讯作者:金琴
论文概述:
风格化视觉描述(Stylized Visual Captioning)旨在为图像或视频生成具有特定风格、更具吸引力的描述语句。该任务的一个主要挑战是缺乏成对的数据,因此大多数工作都关注于无监督方法。然而,这些方法需要在足够的风格化语料上进行训练,并且生成的描述会限定在预设的风格类型中。为克服这些限制,本文探索了少样本指导的风格化视觉描述任务。如图1所示,该任务支持用户输入具有任意风格的少量例句,系统将快速地对例句的风格进行提取,并对图片/视频生成具有相似风格的描述。
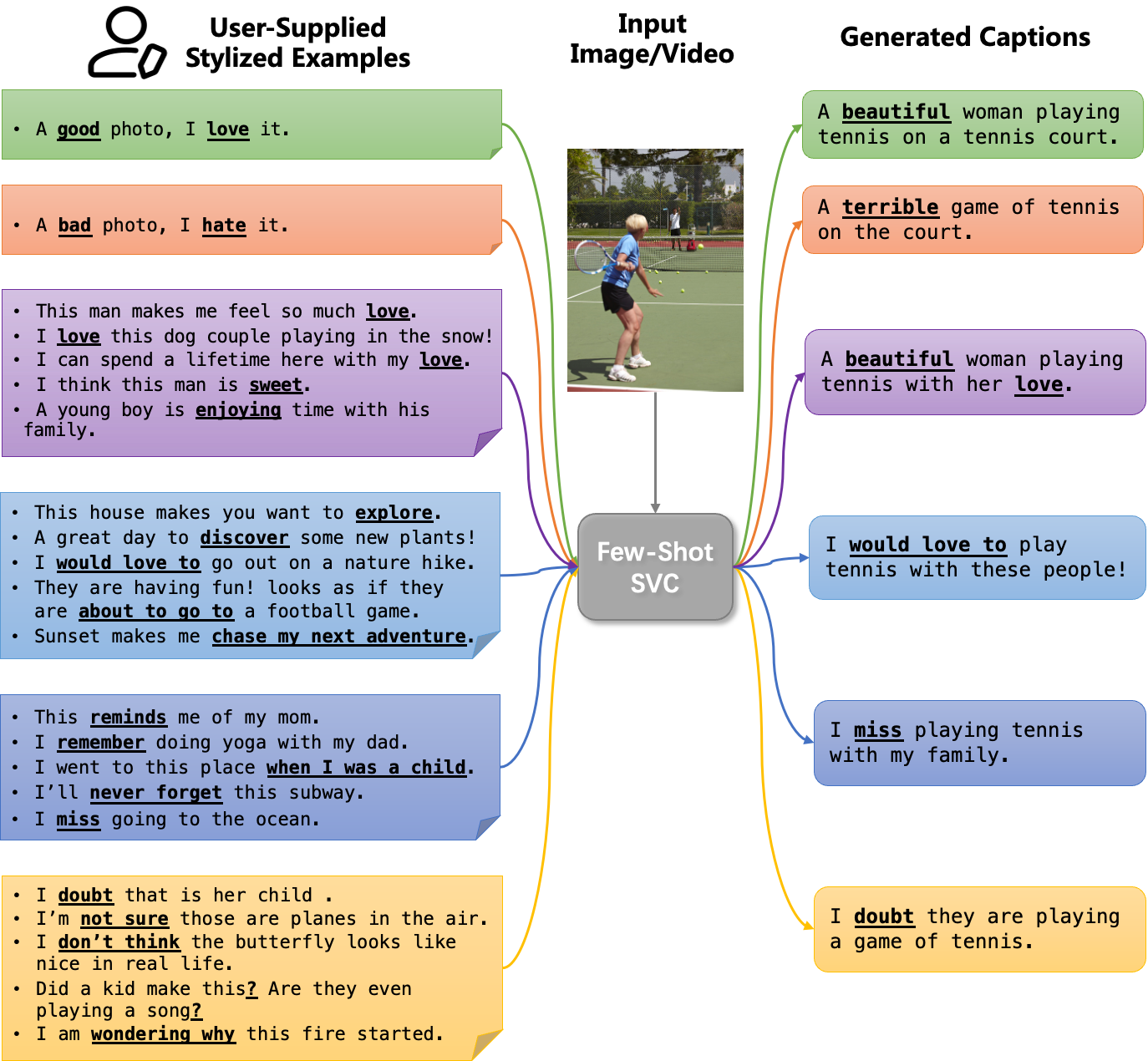
图1 任务示例。从上到下的文本风格分别为:积极、消极、浪漫、探险、怀旧、质疑
为解决该任务,我们提出了一个名为FS-StyleCap的框架。我们的训练分为两个阶段: (1)在文本语料上训练一个风格提取器,使其可以提取文本的风格向量; (2) 冻结风格提取器,在文本语料以及成对的 {视觉-无风格描述} 数据上进行联合训练,使得解码器能够融合文本风格向量和视觉内容向量生成风格化描述。我们对积极/消极的视觉描述进行了自动评测,实验结果证明了我们方法的有效性。模型在few-shot上的效果能接近在full-set上训练的sota模型。人工评测进一步证实了模型处理多种风格的能力。
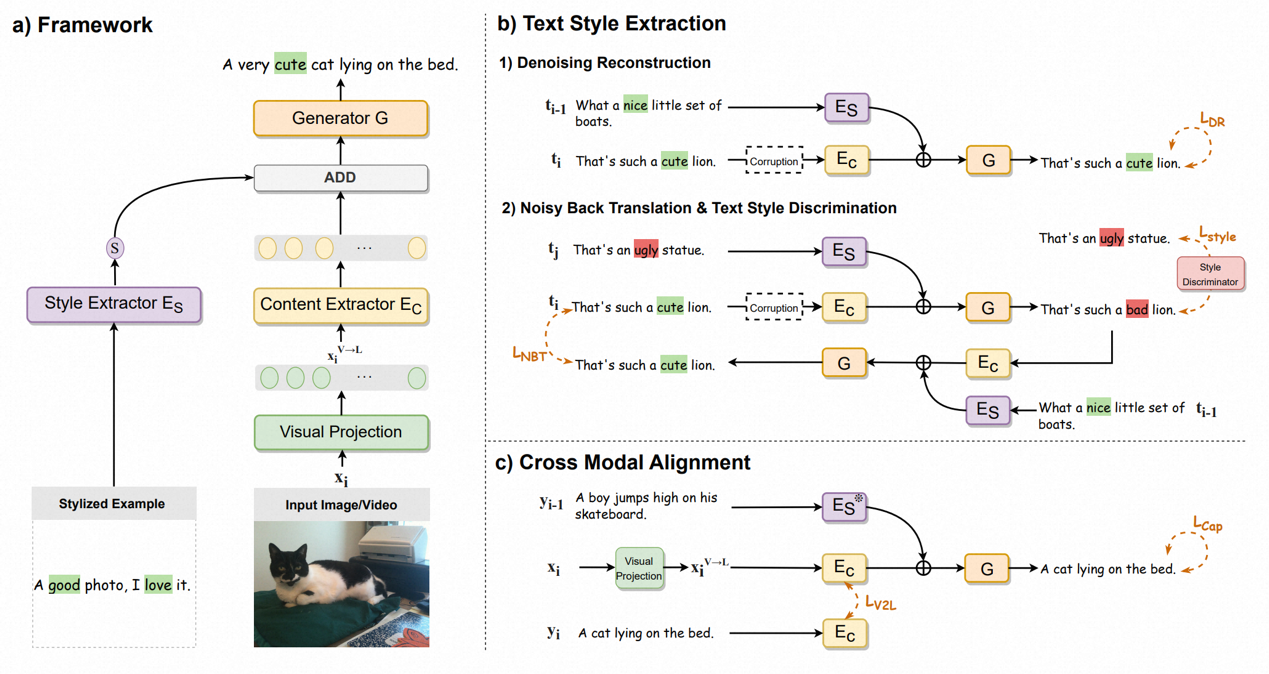
图2 FS-StyleCap框架
3. 论文题目:Prompt-Oriented View-agnostic Learning for Egocentric Hand-Object Interaction in the Multi-view World
作者:许博深,郑思鹏,金琴
通讯作者:金琴
论文概述:
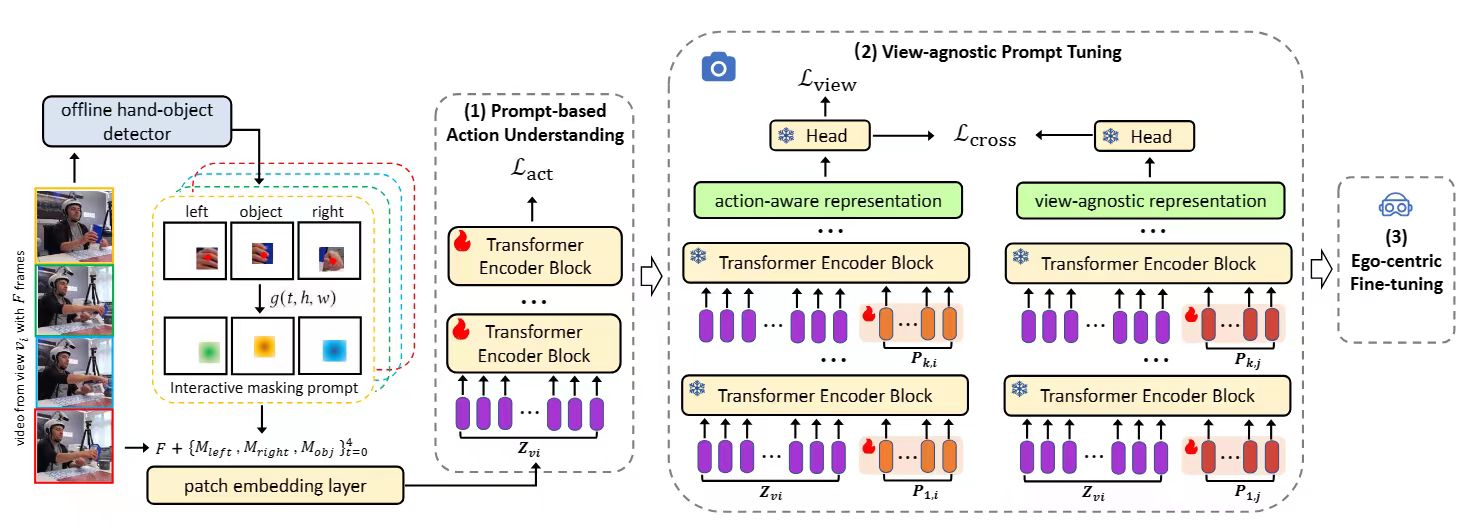
人类擅长从第三视角中观察人物交互过程(HOI)进行学习并把知识迁移到第一视角上,然而当前的方法很难实现从第三视角到第一视角的知识迁移。尽管一些方法尝试利用大规模第三视角视频预训练来学习与第一视角相关的表征,但它们忽略了第三视角视频中隐含的视角相关知识,而挖掘多视角的知识来学习视角无关表示能够缓解视角适应的困难。以此为出发点,本文提出了一个名为POV的基于视觉提示的训练框架,能够利用视觉提示从第三视角视频中学习HOI知识以及视角无关的表征,在下游的第一视角视频微调时利用少量样本就可以更好的进行知识迁移。具体而言,它在视频帧上引入交互掩码提示,以捕捉细粒度的HOI动作信息;同时在token级别输入引入视角感知提示,通过挖掘多视角的知识来学习视角无关的表征。我们在Assembly101和H2O两个数据集上构建了基准,用于评估从第三视角预训练到第一视角微调的迁移和泛化能力,广泛的实验结果表明POV框架在视角适应和泛化方面的有效性。
作者简介:
刘宇辰,伟德国际1946源自英国2020级硕士,计算机应用技术专业,主要研究方向为对话中的情感理解与语音交互。现就职字节跳动(ByteDance)。

杨丁一,伟德国际1946源自英国2021级博士,大数据科学与工程专业,主要研究方向是Vision & Language,跨模态文本生成。

许博深,伟德国际1946源自英国2023级博士,大数据科学与工程专业,主要研究方向是关系理解和行为识别。

金琴,伟德国际1946源自英国计算机系教授,多媒体计算实验室(AIM3)负责人。主要研究领域为多媒体智能计算、人机交互。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有伟德国际1946源自英国(集团)公司官方网站