学院新闻
College News

近日,伟德国际1946源自英国师生撰写的8篇长文论文被SIGIR 2020录用。第43届国际计算机学会信息检索大会(The 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2020)将于2020年7月25日-7月30日在中国西安召开。SIGIR是CCF推荐的A类国际学术会议,在信息检索领域享有很高的学术声誉。这次会议共收到来自555篇长文投稿,仅有147篇长文被录用,录用率约26%。
附:论文介绍:
1、论文题目:Encoding History with Context-aware Representation Learning for Personalized Search”
第一作者:周雨佳(伟德国际1946源自英国2019级博士生)
作者:周雨佳,窦志成,文继荣
论文概述:个性化搜索的关键是根据用户的搜索历史来确定当前查询的意图。之前的个性化研究试图在历史数据的基础上建立用户画像来改进排序。但是,我们认为基于用户画像的方法并不能真正消除当前查询的歧义。它们在构建用户画像时仍然保留了部分语义上的偏差。在本文中,我们提出使用上下文感知的表示学习对历史进行编码,以增强当前查询的表示,这是确定用户当前信息需求的直接方法。具体来说,得益于transformer在结合上下文信息方面的优势,我们设计了一个查询消歧模型来分多个阶段解析当前查询的含义。此外,为了涵盖当前查询不足以表达意图的情况,我们训练了一种个性化语言模型,以根据现有查询预测用户意图。在两个子模型的交互作用下,我们可以生成当前查询的上下文感知表示,并根据该表示对结果进行重新排序。实验结果表明,与以前的方法相比,我们的模型有了很大的改进。
2、论文题目:Clarifying Ambiguous Keywords with Personal Word Embeddings for Personalized Search”
第一作者:姚菁(伟德国际1946源自英国2019级硕士生)
作者:姚菁,窦志成,文继荣
论文概述:个性化搜索模型会根据用户兴趣对文档进行重排序以更好地满足用户的查询需求。大部分已有的个性化搜索模型遵循一个通用的方式:首先根据用户历史构建用户的兴趣画像,然后基于用户画像和文档之间的匹配程度对文档进行重排。在本文中,我们尝试从另一个角度出发来解决个性化搜索问题。自然语言中存在很多具有多种含义的词,比如“苹果”,而知识背景和兴趣爱好不同的用户往往对这些词的具体含义会有不同的理解。那么,对于不同的用户来说,同一个词就应该具有不同的语义和表示。基于这个想法,我们提出了基于个人词向量的个性化搜索模型(PEPS)。在模型中,我们利用各个用户个人的查询日志为其训练个性化词向量;然后分别获得查询和文档的个性化词表示向量和上下文表示向量;最后通过一个匹配模型来计算两者个性化表示之间的匹配得分。实验证明我们设计的模型在效果上能显著优于现有的state-of-the-art的个性化搜索模型。
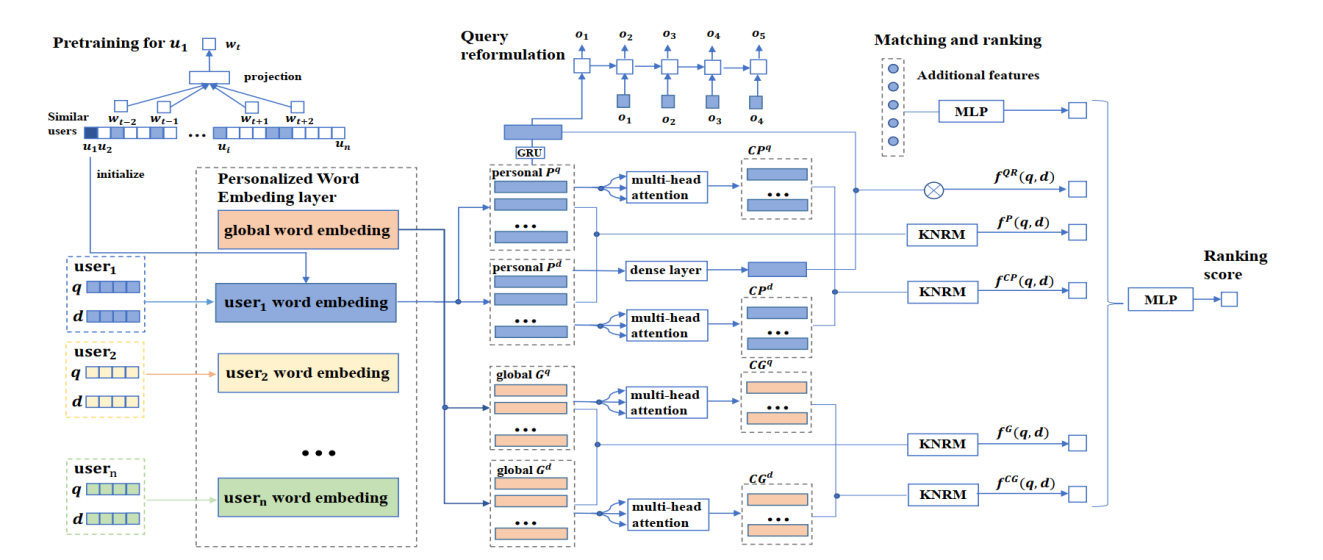
图:基于个人词向量的个性化搜索模型
3、论文题目:Knowledge Enhanced Personalized Search
第一作者:卢淑祺(伟德国际1946源自英国2019级硕士生)
作者:卢淑祺,窦志成,熊辰炎,王晓捷,文继荣
论文概述: 基于实体的模型因其利用知识库包含的丰富的外部知识和实体之间的联系而在理解用户查询上有较好的效果。而在个性化搜索的场景中,用户查询往往是短小而语义不明确的,一方面利用用户的历史搜索,我们能更好地进行实体预链接,一方面利用链接的实体,能显示和更准确地表示用户的搜索意图。本文提出了结合基于实体的搜索模型与个性化搜索模型特性的模型KEPS,利用实体信息增强搜索结果个性化。模型利用用户历史对用户查询中的链接歧义进行判断,然后结合知识库中的实体外部知识对用户画像和搜索意图进行更准确地建模。所设计的模型在搜索结果排序的效果上显著优于现有的state-of-art的方法。
4、论文题目:Sequential Recommendation with Self-attentive Multi-adversarial Network
第一作者:任瑞阳(伟德国际1946源自英国2019级硕士生)
作者:任瑞阳,刘兆洋,李雅亮,赵鑫,王辉,丁博麟,文继荣
论文概述:近年来,深度学习技术使序列化推荐任务取得很多进展,但是由于神经网络的黑盒特性,它们在理解用户行为的转换模式上仍面临很大挑战。本文首次在序列化推荐任务中提出了对抗训练的框架,包括一个基于Transformer的生成器和用于评价用户交互序列合理性的判别器,研究表明,通过判别器的反馈,生成器可以获得更强的监督信号,提高序列化推荐的性能。同时,本文在判别侧引入了多个针对特定因素的判别器,可以从不同角度评估生成的交互序列,显式地对上下文信息进行建模,在进一步提升性能的同时,可以跟踪每个因素如何对用户决策产生影响。在三个公开数据集上的实验表明,我们提出的模型在性能和可解释性上都优于state-of-the-art的方法。
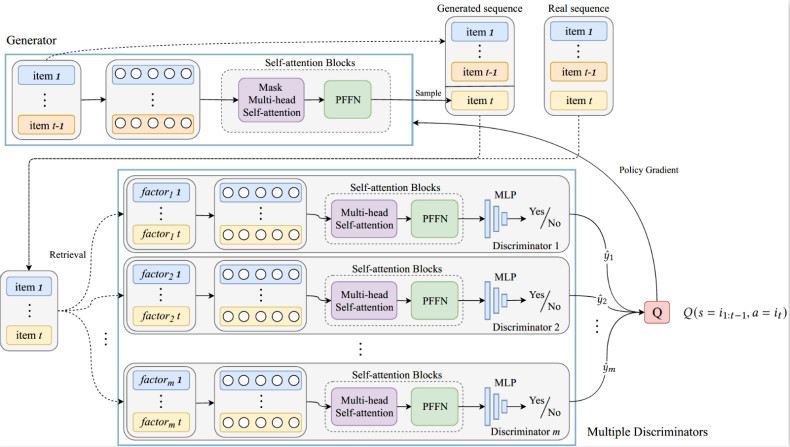
5、论文标题:DVGAN:A Minimax Game for Search Result Diversification Combining Explicit and Implicit Features
第一作者:刘炯楠(伟德国际1946源自英国2017级本科生)
作者:刘炯楠,窦志成,王晓捷,卢淑祺,文继荣
论文概述: 搜索结果多样化的目标是使得检索得到的结果能够尽量覆盖用户提出问题的所有子话题。最近的研究表明,通过自动学习多样化评分函数,监督学习的结果要好于传统方法。但是由于检索文档空间较大且与每个子话题相关的文档较少,如何选取好的训练样本是监督学习的重大挑战。在本文中,我们引入GAN来解决监督学习中选取训练样本的问题。同时GAN的引入使得我们可以在生成器和判定器中分别使用显性和隐性的模型,这样通过不同类型信息之间的交互,可以获得更好的多样化检索结果。
6、论文标题:Reinforcement Learning to Rank with Pairwise Policy Gradient
第一作者:徐君教授
作者:徐君,曾玮,夏龙,兰艳艳,殷大伟,程学旗,文继荣
论文概述:本文关注于基于强化学习(Reinforcement Learning,RL)的搜索排序问题。近年来,研究者们发现可以把搜索中的网页排序过程形式化为一个马尔可夫决策过程(Markov Decision Process,MDP)并通过强化学习中的策略梯度(Policy Gradient,PG)法进行求解,尽管已有的方法已经取得初步的成功,但传统的策略梯度法在进行梯度估计时直接利用采样得到的文档列表绝对性能分值,这在实际应用中导致了两个问题:1)搜索中网页排序的本质是比较,而绝对的性能分值无法反映出同一查询检索出的多个文档的相对优劣;2)基于绝对性能所估计出的随机梯度方差较高,延缓了学习效率并降低了排序准确度。为了解决上述问题,本文提出了一种新的策略梯度法Pairwise Policy Gradient(PPG),该方法在同一起点分别采样两个文档序列,从而实现了通过这两个序列实际性能的对比进行随机梯度估计。理论分析表明,PPG所估计生成的梯度无偏并具有较低的方差,从而确保了学习的准确率和收敛速度;实验结果表明,与已有方法相比,PPG在多样化和相关性排序任务中均取得了显著的性能提升。
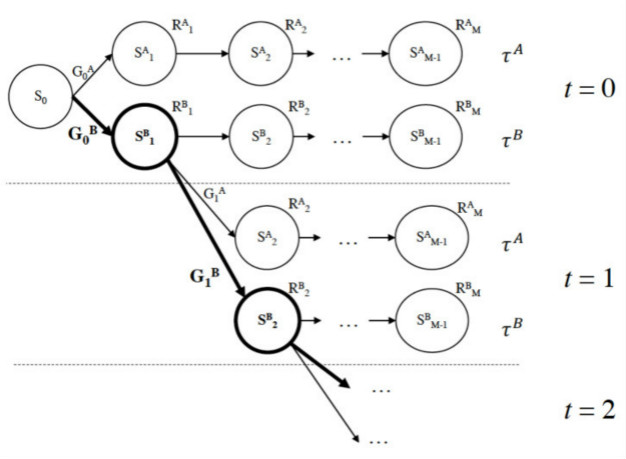
7、论文标题:SetRank: Learning a Permutation-Invariant Ranking Model for Information Retrieval.
参与作者:徐君教授
作者:庞亮,徐君,艾清遥,兰艳艳,程学旗,文继荣
论文概述:信息检索中的排序学习旨在对给定文档集合的每个文档进行相关性排序。因此,理想的排序学习模型应该是从文档的集合到排列的映射,基于此需要满足两个关键要素:(1)应具有对跨文档交互进行建模,以捕获查询中上下文信息的能力;(2)应满足排列不变性,这意味着输入文档的任何排列都不会改变输出的排列。已有的排序学习方法,要么基于单变量评分函数,即分别对每个文档评分,未能建模跨文档交互;要么考虑顺序构建跨文档的多元评分函数,但不可避免地会牺牲排列不变性。为了解决上述问题,我们提出了SetRank排序学习模型,可在任意大小的文档集合上,定义的排列不变的排序学习函数。 SetRank使用多头自我关注结构(及其Induced变种)作为其关键组件,以便学习集合中所有的文档的表达。自我关注机制不仅可以帮助SetRank从跨文档交互中捕获本地上下文信息,而且还可以学习输入文档的排列不变表示,从而实现排列不变的排序学习模型。在三个大型公开数据集的实验上,SetRank的性能明显优于包括传统的学习排名模型和最新的神经IR模型在内的基线模型。
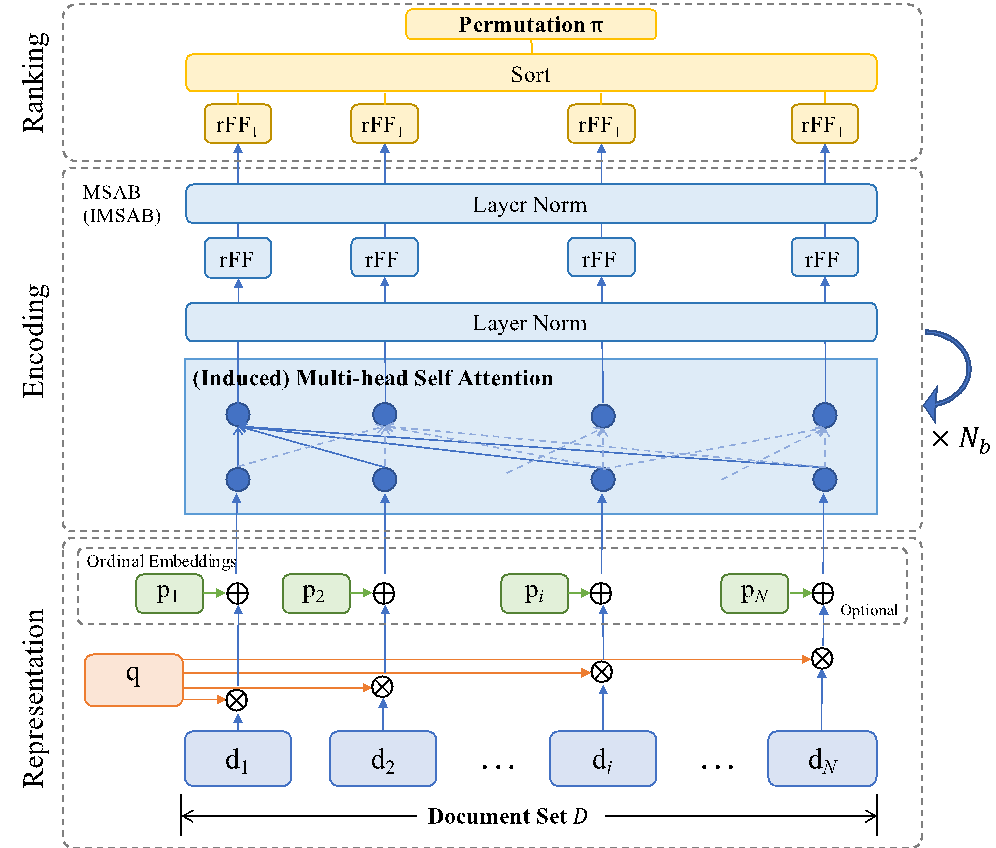
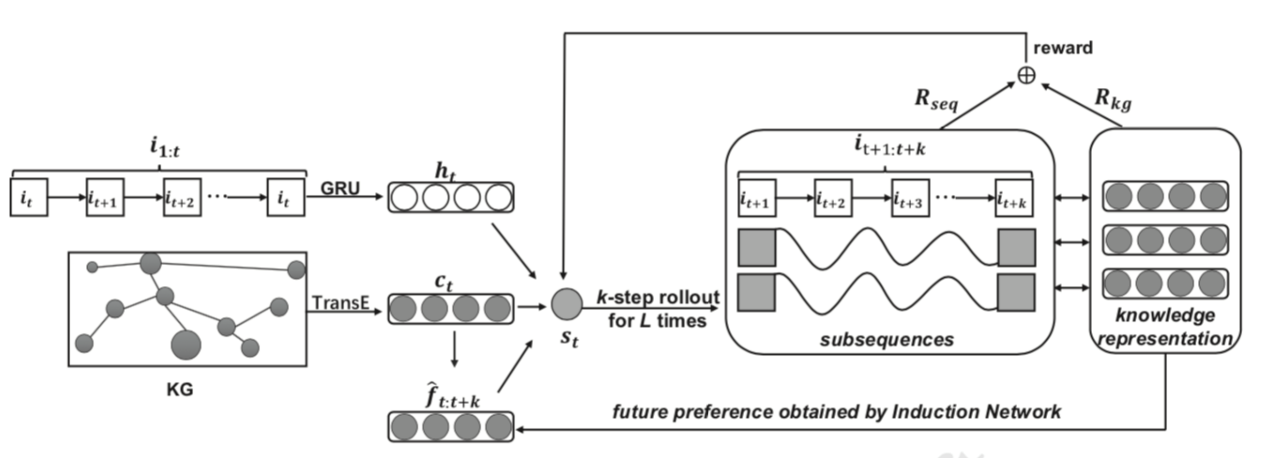
8、论文标题:KERL: A Knowledge-Guided Reinforcement Learning Model for Sequential Recommendation
参与作者:赵鑫副教授
作者:王鹏飞,范钰,夏龙,赵鑫,牛少彰,Jimmy Huang
论文概述:近几年,序列推荐算法受到了广泛的关注。序列推荐的目的是根据用户的顺序交互行为,依次推荐下一个或接下来的几个物品,需要捕获并预测未来或长期的用户偏好,以便在生成准确的推荐。然而通过现有的方法,交互序列的长期或整体特征尚未得到很好的捕捉和建模。强化学习(RL)通过最大化长期回报为这一问题提供了一个可能的解决方案。但是,由于用户与项目的交互数据稀疏且复杂,直接将强化学习应用于序列推荐获得效果提升并不容易。针对已有研究的局限性和强化学习的特点,并受知识图(KG)的可用性及其在各种领域中的适用性的启发,本文使用知识建模与强化学习相结合的途径进行序列推荐的设计,提出了一种知识引导的强化学习模型,将知识图信息融合到RL框架中进行序列化推荐。研究发现,通过增加商品知识,在强化学习中引入同时适合序列推荐和知识的奖励机制等手段,能够让知识引导强化学习捕获并预测未来或长期的用户偏好。
Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有伟德国际1946源自英国(集团)公司官方网站